How Overton benchmarks the percentage of documents in a set that are cited in policy
Given a large set of articles it can be helpful to know if the %age of articles cited in policy matches what you might expect – what’s “normal”.
But determining expectations is difficult as it depends on the age, subject area and type of the articles in question. As a very general rule we sometimes say that you should expect around 5% of scholarly articles to be cited in policy: in reality for documents in public health, economics or international development, for example, it could be as high as 60%+, and for quantum physics or drama as low as 0.1%.
When we’re helping users understand their data we’ll sometimes run a simple benchmarking experiment that takes some of this into account by compensating for publication date and venue (as a stand in for subject area) biases – we compare the set of articles to another, randomly selected set of articles from the same journals and published in the same kind of timeframe.
More specifically the steps we take are:
- For each article in the input list
- We use OpenAlex to find all articles published in the same journal in the same short time window – a month before publication or a month after publication. This is the possible comparands set for this article
- If the possible comparands set contains fewer than 80 articles – perhaps the journal only publishes a few articles a month – the time window is expanded to between two months before publication and two months after publication
- If the possible comparands set still contains fewer than 80 articles the time window is expanded to three months before and after the article publication date
- If there are no articles to compare to in this larger time window then we skip the article and exclude it from analysis
- We treat everything with a DOI as an article, and don’t include items that OpenAlex considers paratext (e.g. tables of contents, front covers, mastheads, editorial board listsings)
- At the end of the process for an input list containing n articles we have n corresponding possible comparand sets
- We then run the following experiment 1,000 times:
- Create a new empty list
- Pick a single entry at random from each of the possible comparand sets in turn and add it to the list we created above
- The list now contains n items. This is the matched comparands set (each article in the matched comparand set has the same journal and approximately the same publication date as one of the articles in the original input list)
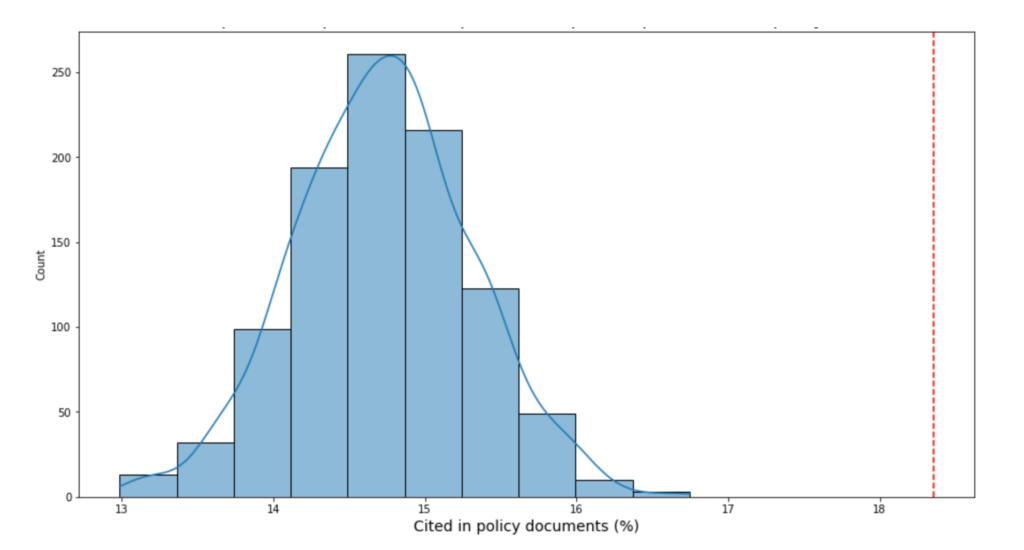
- Calculate the %age of articles on the matched comparands set that are cited in policy
- We then plot the output (the %age of comparand articles cited) of each run and from that we can derive the median outcome which we can use to compare to the %age cited figure for the input set.
Caveats and limitations
This is still a very rough, indicative approach. In particular some shortcomings to be aware of are:
- Multidisciplinary journals like Nature & PLoS One, for example, may publish articles from a mix of subject areas, so the articles of a similar age picked randomly from these venues are less likely to be on comparable topics.
- Article types – we look for articles published in the same journal around the same time and ignore paratext (see above), but there is no easy way to tell if a comparand article we’ve selected is, for example, a book review or an editorial, or a systematic review or a short letter. Ideally a proper comparand would be of the same type as its input article.
- Incorrect publication dates – getting accurate publication dates is a long standing bugbear for anybody working with scholarly data. We rely on the dates in OpenAlex (which in turns collects data from publishers and Crossref) being correct.